![]()
OpenCL (Open Computing Language) is a new standard framework which allows for simple coding of parallel and stream processing by taking full advantage of the huge computational power of modern GPU (Graphics Processing Units or graphics 'cards'). Until OpenCL, GPU computing was a largely propriatary and hardware centred area, but OpenCL provides a way for this to become a more central part of modern computing. For example, OS X Snow Leopard already uses OpenCL and Windows 7 plans to support it through Direct X 11.
The motivation for the creation of OpenCL was to create a generic method for computation to be split across the CPU and GPU or and other processors (e.g. FPGAs), irrespecitve of the operating system or hardware. This includes defining the computational kernels (small blocks of code which are run in parallel) and the coordination of the shared memory allocation between the processors. In order to achieve this, the OpenCL standard includes a language based on ANSI C for definition of the computation kernels and APIs that define and control each of these processors as well as the memory allocation.
The layout and style of OpenCL has many parallels with CUDA(Compute Unified Device Architecture) and Cg (C for graphics). In many ways, OpenCL is a level of abstraction above CUDA and Cg (on the NVIDIA platform OpenCL runs through CUDA), but the same ideas of stream processing is consistent in all cases. Memory allocation and buffering is controlled by the CPU and the GPU(s) and the additional CPU cores are then used to execute each kernels.
OpenCL's benefits over Cg is that it is built for scientific computing and so you can operate on the data in a fast, efficient and accurate way without having to convert your computation problem to the limitations of the graphics paradigm of verticies and triangles. The advantage of OpenCL over CUDA is that each kernel will run on multiple systems, not just NVIDIA hardware, but unfortunately this can mean that the OpenCL code is consequently slower( but this will hopefully be improved with better drivers in the future).
Once code is prepared for parallel execution (either multithreaded or written for CUDA etc) then there is very little rewriting required to optimise the code for OpenCL. Kernels in OpenCL are written in a modified version of C and saved to a file with the extension '.cl'. An example of converting a sequential loop to OpenCL is shown below.
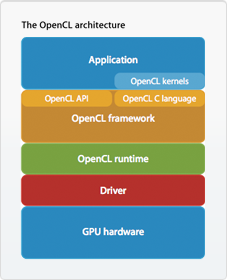
The main part of the OpenCL framework is the handling of passing data to and from your processing environment and, the compiler of the OpenCL code. The main stages of execution are shown below. The key parts OpenCL handles are setting up and coordinating your environment (with n processors -including multiple GPUs) so that it can then distribute the data and compile the code efficiently. It also then has control of each process. This means it can 'bottle' the main progress of the code until the completion of all the desired operations, when either more operations can be performed or the data from the GPU can then be handed back to main memory on the CPU. OpenCL does depend on the driver provided by hardware in order for it to be supported. A visualisation of this is shown in the diagram below right.
An example converson from C code to an OpenCL kernel below illustrates the differences of sequential stream computing. The task is to perform a 2-D convolution. In Standard C code this is:
void Convolve(float * pInput, float * pFilter, float * pOutput,
const int nInputWidth, const int nWidth, const int nHeight,
const int nFilterWidth, const int nNumThreads)
{
// N.B. This assumes both the convolution kernel and the image are square
for (int yOut = 0; yOut < nHeight; yOut++)
{
const int yInTopLeft = yOut; for (int xOut = 0; xOut < nWidth; xOut++)
{
const int xInTopLeft = xOut; float sum = 0;
for (int r = 0; r < nFilterWidth; r++)
{
const int idxFtmp = r * nFilterWidth;
const int yIn = yInTopLeft + r;
const int idxIntmp = yIn * nInputWidth + xInTopLeft; for (int c = 0; c < nFilterWidth; c++)
{
const int idxF = idxFtmp + c;
const int idxIn = idxIntmp + c;
sum += pFilter[idxF]*pInput[idxIn];
}
}
const int idxOut = yOut * nWidth + xOut;
pOutput[idxOut] = sum;
}
}
}
When thinking of converting this to OpenCL, we must first think of unwrapping the loops we put in to iterate through the arrays.
__kernel void Convolve(const __global float * pInput,
__constant float * pFilter,
__global float * pOutput,
const int nInWidth,
const int nFilterWidth,
const int nNumThreads)
{
const int nWidth = get_global_size(0);
const int xOut = get_global_id(0);
const int yOut = get_global_id(1);
const int xInTopLeft = xOut;
const int yInTopLeft = yOut;
float sum = 0;
for (int r = 0; r < nFilterWidth; r++)
{
//since linear array of floats, need to index correct element
const int idxFtmp = r * nFilterWidth;
const int yIn = yInTopLeft + r;
const int idxIntmp = yIn * nInWidth + xInTopLeft;
for (int c = 0; c < nFilterWidth; c++)
{
const int idxF = idxFtmp + c;
const int idxIn = idxIntmp + c;
sum += pFilter[idxF]*pInput[idxIn];
}
}
const int idxOut = yOut * nWidth + xOut;
pOutput[idxOut] = sum;
}The above code shows the first simple stage of unrolling. More advanced optimisation can be performed by then unrolling the iteration over the kernel. If your interested, This is discussed in more detail at the page this example is taken from : Image Convolution Using OpenCL.
The main application for this course is Spatial Computing. How can OpenCL apply in this context? By Setting up the buffers for OpenCL data as OpenGL buffers instead, you can use OpenCL to perform your computation (at much faster data rates than on the CPU) and then plot these results in OpenCL. There is a command GL_INTEROP which can be used to configure this. An example of this can be further investigated in the links at the bottom of the page with a procedurally generated world.
Presentation given 4th March 2010 - Download here
Example Code - Download here
OpenCL / OpenGL interface Code example (Via Apple)
OpenCL Programming Guide for Mac OS X
OpenCL Demonstration - YouTube
OpenCL/OpenGL interoperabilty example (Advanced)