Concept
_object.browser aims to explore the relation that an observer has with those viewed in photographs and, indirectly, public real world spaces. This project uses a library of photographs from MySpace profiles (MySpace). Each MySpace user chooses their profile picture to visually identify themselves within the online community. _object.browser rapidly displays these images to simulate the density of visual identities encountered in browsing an online community or moving through crowded public area.
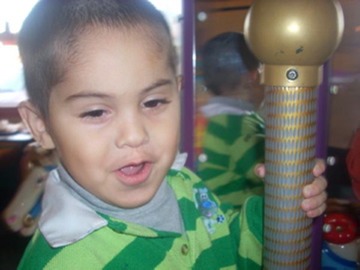
Initially, a random series of photographs from the library are displayed in black-and-white. As the observer sits in front of the screen, the horizontal position of their face is detected. When this occurs, the image stream changes to color begins to display images with faces positioned similarly (images 1-3). Recognizing this capability, the observer is able to control navigation through this identity database. However, this is only a limited amount of control, as each position of the observer's face on the horizontal axis may correspond to dozens of images, of which one is displayed randomly at each moment.
After some time, the observer is granted an additional amount of control. When the user keeps their face in the same position, a vertical bar appears, overlapping the succession of photographs. The longer the face is kept still, the wider this bar appears (images 4-5). If the observer continues to view the work, the bar will become more opaque and will grow at an increasing rate. Hence, the presence of this vertical bar is related to the observer's focus. (As a consequence, an impatient observer may stop viewing the work before noticing the vertical bar.)
It soon becomes clear that the vertical bar is a segment of the input video stream, centered on the middle of the observer's face. The input video is displayed in black-and-white, contrasting with the primarily color photographs in the image library. Suddenly, this vertical bar begins to expand rapidly, and the observer's image will fill the entire screen, making the photograph stream all but invisible, unless the observer moves rapidly. Eventually, even this is ineffective. With the vertical bar expanding to fill the screen, the overlapping input video changes from black-and-white to color and quickly becomes opaque (images 6-7). Finally, the input video stream is displayed in series with the library images, integrating the observer's image fully with the images of the observed (images 8-10).
Implementation
_object.browser contains computer vision, video capture, and video display software developed in C++ using the OpenCV library (Davies). File management software was written in MATLAB. The Viola-Jones method is used for face detection with both the image library and input video stream (Hewitt). The image library was filtered to contain images of the proper size and then processed by the face detection software to find the center of the face positions within each image. Images without detected faces were discarded. At this point, the images containing a single face were detected manually. A list of images is compiled for each position and stored to disk. Running the presentation software, this list of positions is loaded into memory and traversed to retrieve an image with a given horizontal position, which is determined by the detected position of the observer's face.
Time-based progress through the work is based on the number of frames displayed since the observer is detected and the number of frames for which the observer has remained still (this is reset to 0 whenever the observer moves greater than a certain distance). Additionally, when the observer remains still for a number of frames, the progress is quickened, giving slight variation in the time of the experience.
Images are displayed at approximately one frame for every 130 milliseconds (7.7 frames per second) on an Apple Macbook with a 2 GHz Intel Core 2 Duo processor and 1 GB of RAM.
Background
The technique of rapid display of images was inspired by both film montage techniques and concatenative sound synthesis in music. Considering Eisenstein's montage theory, the display of images acts as both metric montage, with a (approximately) fixed length of display for each image, and intellectual montage, by juxtaposition of the observer and observed (Zettl). In concatenative sound synthesis, a library of sounds are analyzed. Then, controlled by a set of input parameters, these sounds are chosen stochastically and sounded in a rapid manner, creating a cohesive sound event (Schwarz). Likewise, the structure of the work as it progresses over time is inspired by musical composition form.
Testing and Future Work
_object.browser was tested by two observer after its creation. Although not ideal conditions, several significant discoveries were made in this process. The first observer was given no information about the work besides that it was a visual work lasting 2-3 minutes to be viewed on the computer screen. The second observer was additionally told that it was an interactive work used computer vision. Surprisingly, neither user moved their head significantly nor realized that they had the ability to control the images shown my moving their head. The second observer realized a relationship between their motion and the width of the bar, although he did not understand the relationship entirely.
However, both observers were able to understand the general concept of the work. The first observer described the experience as "being birthed" and then being "integrated into society." The second observer recognized the phenomenon of one's attention being drawn to the face within the image. Additionally, both observers were pleased and surprised to see their own face as the bar widened, and saw the relation between their face and those in the photographs at this point and beyond.
These observations raise certain questions that have yet to be considered thoroughly. First, the issue of how much information to give to the observer prior to the experience has not been decided, although there is much that would be lost by giving too much information to the observer beforehand, as they would not have the sense of discovery within the process. In any case, the fact that the observers were not able to understand the system does not necessarily point to failure. If the work were to be distributed for use on one's own computer, observers would be able to make discoveries over iterated viewing.
Several technical issues more certainly need to be resolved. Although the overall speed of the work is acceptable, there is a significant variation in the speed of the frames changing. Most significantly, in the stage where the observer's face is blended in color with the photographs, the rate slows approximately 30%. Although this could be improved with the use of more efficient algorithms, the best solution would be to modify the software so that a fixed rate could be set. For this to be done, multithreading would need to be implemented into the software. This would also greatly improve efficiency on multicore processors, as the computer vision calculations use a significant amount of processor power.
A second major issue is that the software has a memory leak (memory usage accumulates over time), which makes the software unstable and unfit for distribution. This problem has been traced back to the computer vision API used, OpenCV. In the future, other APIs would be explored for image display.
Acknowledgements
_object.browser was developed for a course taught by George Legrady and Jerry Gibson in the Media Arts and Technology Program at University of California, Santa Barbara. Javier Villegas, Bo Bell, and Wesley Smith provided assistance with computer vision algorithms and software. Sarah Harris and Greg Shear tested the prototype and agreed to be recorded for demonstration videos. (See "Testing and Future Work.")
References
- Davies, Bob, et al. OpenCV. http://opencvlibary.sourceforge.net.
- Hewitt, Robin. "Seeing With OpenCV: Finding Faces in Images."
- Levin, Golan. "Computer Vision for Artists and Designers: Pedagogic Tools and Techniques for Novice Programmers." http://www.flong.com/texts/essays/essay_cvad.
- MySpace. http://www.myspace.com.
- Schwarz, Diemo. "New Developments in Data-Driven Concatenative Sound Synthesis." International Computer Music Conference Proceedings 2003, 443-446.
- Zettl, Herbert. "Sight Sound Motion: Applied Media Aesthetics." Belmont: Wadsworth Publishing Company, 1990.
 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
10