 |
|
|
|
|
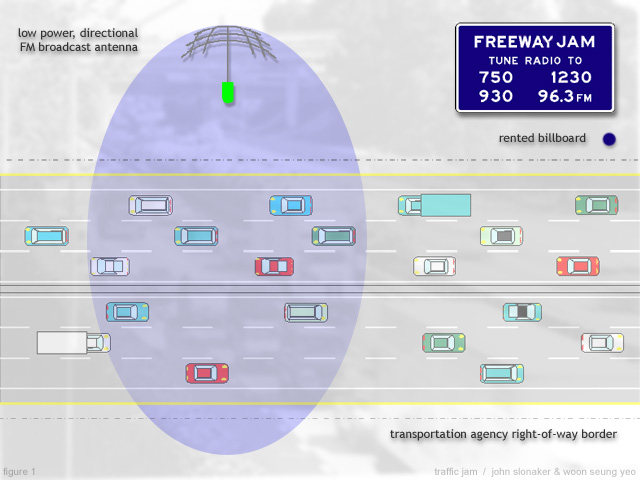
freeway jam
|
|
|
|
large scale interactive sound installation
santa barbara, california
mat200a winter 2002 final project proposal
John Slonaker / Woon Seung Yeo
|
|
|
introduction
|
|
Freeway Jam is a large scale interactive sound synthesizing and broadcasting system that uses real time data generated by machine vision, human performers and audience members as the basis for each sound object. Prospective audience members for this event will be drawn from motorists on a selected stretch of freeway. Each driver can act to alter the sound object corresponding to his or her vehicle, while the collective pattern of traffic on the freeway segment will determine the overall mood of the sonic experience. The drivers, or their passengers, can also supply source material via cell phone to be incorporated into the mix. The system will be able to operate in a completely automated mode or in a mode that allows interaction between audience members and human performers.
|
|
audience experience
|
|
Potential listeners and participants in Freeway Jam are drawn from drivers, and their passengers on a selected freeway segment. People are first notified of the system's existence by a billboard inviting them to tune their FM radio to the specified frequency band. If they so choose, the first broadcast they will hear is a voice recording briefly describing how they may interact with the system once the audio program begins.
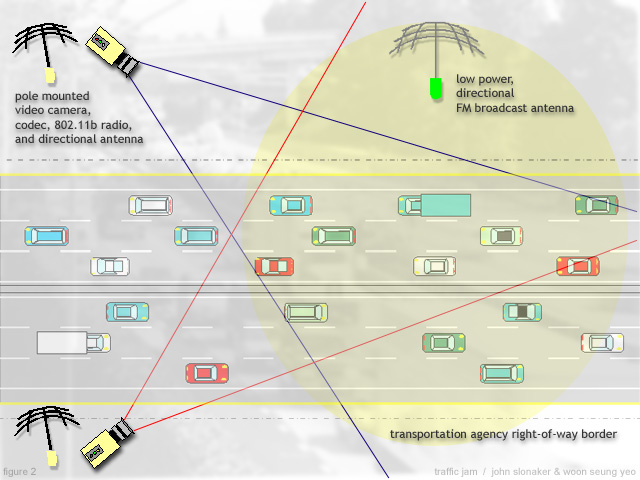
As the listeners progress down the freeway, this broadcast fades out and the main audio program fades in. This program consists of several sound objects in different registers, pan positions and amplitudes. When the driver turns his/her vehicle's lights on, the sound object corresponding to that particular vehicle becomes a sine wave whose frequency roughly matches the register of the original sound. This informs the listener which object he/she can manipulate. Once the driver turns his/her lights off, the sound object reverts to its original state. Subsequent light flashes will alter various parameters of the sound in unpredictable ways.
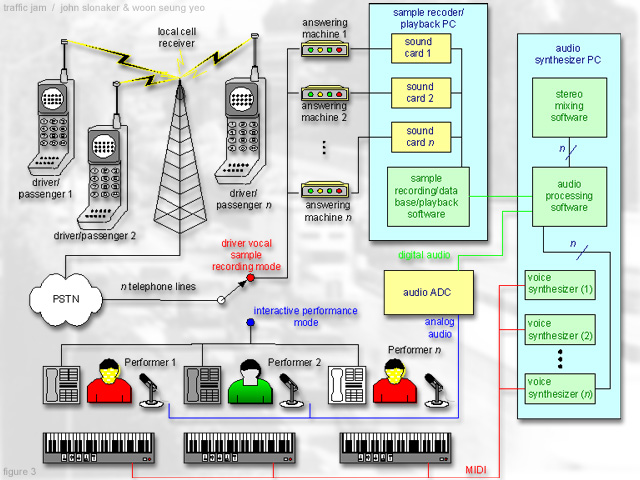
The driver, or passengers, may also call a number, as specified in the voice recording, on a cell phone. In some cases, the call will be answered by an automated greeting instructing the caller to leave a brief message. The resulting audio sample will then be processed and incorporated into the mix of sound objects for a brief period. At certain times, human performers will be available to answer calls. In this case, listeners can suggest specific ways for the performers to process existing sound objects or vocal samples. Performers could also improvise melodies or other sound objects, or record and process their own vocal samples, in response to suggestions from callers.
|
|
technical overview
|
|
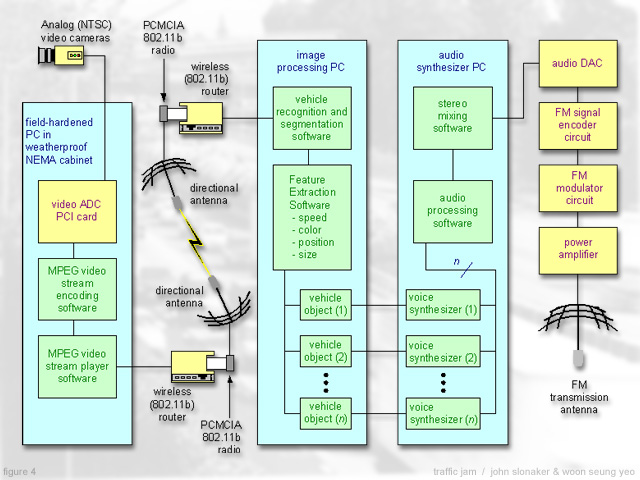
Several subsystems are necessary to provide for the various inputs to the overall system. Video input will be provided by outdoor cameras and video codec equipment that will capture a digital visual representation of the vehicles on the selected stretch of freeway. Once encoded, this signal will be transmitted to the central processing, performing and broadcasting area via a wireless digital communication subsystem. A subsystem at the processing center will perform segmentation and feature extraction of each vehicle. Each vehicle, along with its corresponding feature set, will be stored as a separate software object. Software objects for audio input will be created by a subsystem that automatically answers participants' incoming cell phone calls and records them as digital audio files. Finally, a subsystem consisting of human performers using microphones connected to analog-to-digital conversion equipment and MIDI keyboards will provide audio and control input.
The output of the system will be provided by two main subsystems. The subsystem that generates the audio signal is a PC running sound synthesis, sample playback and mixing software. This software will synthesize, process and mix sound objects derived from the various inputs described above. The subsystem that disseminates the stereo mix to the audience is a low power FM broadcasting setup comprised of signal encoding and modulation circuitry, a power amplifier and a directional antenna.
|
|
sound object synthesis
|
|
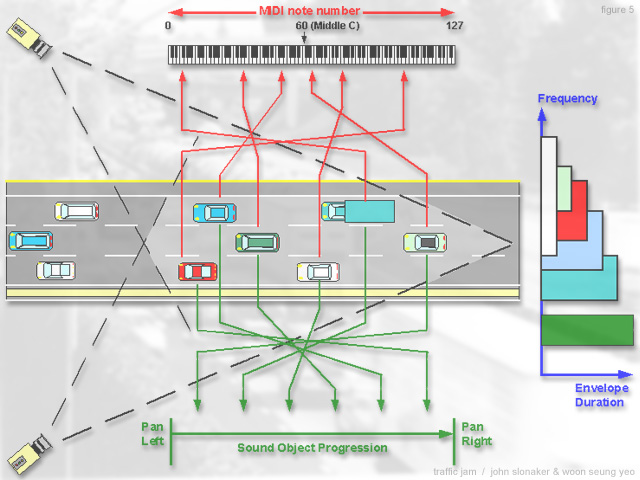
The software that processes the video signal from the freeway cameras will extract several features from each vehicle that enters the detection zone. Among these are speed, color, position and size. These features are then mapped to parameters of each vehicle's corresponding sound object. For example, the speed and longitudinal position of each vehicle is mapped to the corresponding sound object's dynamic pan position. As each vehicle moves from the front end of the detection zone to the back, its sound object pans across the stereo field. Thus, in times of congestion, the listeners hear a relatively dense and homogeneous field of sound that pans relatively slowly across the stereo field. The intension, in this case, is to create a soothing sonic experience for listeners who might feel frustrated by the delay they are experiencing. To the same end, drivers can leave calming messages for the vocal sample player/processor or ask performers to manipulate or improvise sound objects to create a soothing effect. In contrast to the system's sonically benign response to congestion, the sound field has a much sparser and frenetic feel during periods of free flowing traffic. With the stress levels of the listeners at a relatively low level, the system is free to create a more interesting and heterogeneous sonic field.
The size of each vehicle corresponds to its sound object's register. Thus, an "18-wheeler" might generate a sound something like a processed bass drum, tuba or a 100 Hz sine wave, while a "sub-compact" might generate something like a cymbal, a tambourine, high-pass filtered noise, or a 10 KHz sine wave.
Finally, the color of each vehicle will be mapped to the timbre of its sound object. For example, brighter colors and white could generate sounds with a richer spectrum of harmonic overtones, while darker colors and black could generate objects with the majority of their sonic energy in the fundamental frequency.
Human performers can also provide real time, arbitrary control of the above, and other, parameters, either unilaterally or in consultation with callers.
|
|
sound example
|
|
example.mp3 (xx sec, x.xMB)
|